数据科学流程:分析应用程序的6个关键步骤
数据科学流程包括数据科学家收集、准备和分析数据并将分析结果呈现给业务用户的一系列步骤。

数据是现代企业的命脉。越来越多地,通过准确的洞察力和理解,从我们组织的数据中获得最大的好处,会对业务成功产生真正的影响。因此,数据科学家已经成为各种规模公司的关键招聘,无论是IT专业职位还是业务部门的嵌入式职位。
然而,我们并不总是清楚这个术语的意思数据科学家。一个高质量的数据分析师吗?一个有科学背景,又碰巧和数据打交道的人?
当然,数据科学家通常在统计和脚本方面很有经验,他们通常具有技术背景,而不是科学、人文或商业背景。但数据科学的关键要素——使其成为一门科学而不仅仅是一种商业实践——是过程和实验的重要性。
你可能记得在高中时学习过科学方法。科学家提出理论和假设。他们设计实验来检验这些假设,然后要么确认,要么拒绝,更经常的是,提炼这个理论。
基本商业智能和报告通常不遵循这个过程。相反,BI和业务分析师对数据进行筛选、排序、制表和可视化,以支持业务用例。例如,他们可以用图表显示我们公司产品在西部地区的销售正在下降,而且与其他地区相比,这个地区有更多年轻的客户。在此基础上,他们可以证明我们需要改变该地区的产品、市场或销售策略。在BI,最具说服力的数据可视化经常携带论点。
数据科学家采取了不同的方法。让我们继续使用这个销售示例来展示数据科学流程是如何工作的,包括以下六个步骤。
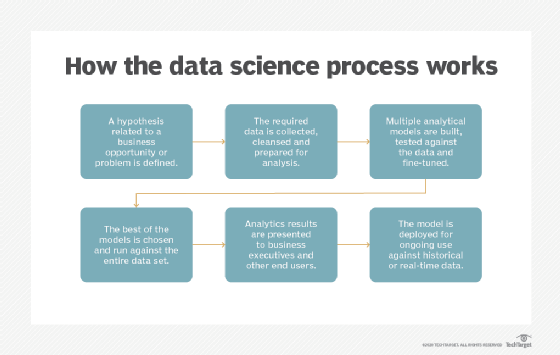
1.确定对业务有价值的假设
在我们的案例中,数据科学家可以根据销售、营销和产品团队提出的问题形成一个简单的假设:我们认为年轻人不太可能购买我们的产品,所以这压低了相对年轻的西部地区的销售。
除此之外,我们还可以提出一些相关的假设,比如:西部地区的顾客不仅年轻,而且年轻人的收入通常比其他地区低,平均收入也比其他地区低。
您已经可以看到,数据科学家必须能够思考相关假设的不同含义,以便设计正确的数据科学实验。只是问一个直接的问题,什么时候分析数据通常比问几个人更没用。为了得到最好的结果,数据科学家应该与商业专家一起梳理出有助于改进假设的边缘案例和反例。
2.收集和准备所需的数据
有了一个假设或一组假设,是时候让数据科学家获得正确的数据并为分析做准备了。
BI团队通常使用来自数据仓库经过清理、转换和建模,以反映业务规则以及分析人员过去如何看待数据。另一方面,数据科学家通常希望在对数据应用任何规则之前查看数据的原始状态。此外,数据科学应用程序通常需要比存储在仓库中的数据更多的数据。
在我们的示例中,公司的数据仓库可能包括关于客户的各种详细信息,但可能不包括他们如何支付产品:通过信用卡、现金、在线支付等。或者,我们可能会发现,由于数据仓库模型修改起来很麻烦,假定的记录系统有点过时,还不包括更新的支付形式——正是对年轻人有吸引力的类型。
因此,数据科学家需要与IT团队合作,以访问可用的最详细的数据源,并将所需的数据收集到一起。这可能是来自ERP、CRM或其他操作系统的业务数据,但它也越来越多地包括网络日志、来自物联网设备的流数据和许多其他类型的数据。的原始数据通常会被提取和装载——或者用行话来说——成数据湖。不过,为了简单和方便,数据科学家通常只在这个早期阶段对一个样本数据集进行工作。
这并不是说数据科学家不会数据准备在所有的工作。当然,他们通常不会像数据仓库开发人员那样将业务模型或预定义的业务规则应用于原始数据。但是他们确实花费了大量时间来分析和清理数据——例如,决定如何处理丢失的值或离群值——并将其转换为适合特定情况的结构机器学习算法和统计模型。
3.试验和调整分析模型
实验设计是数据科学过程中至关重要的一步。的确,有人会说这更像是一门艺术而不是科学。当然,如果数据科学家对业务有很好的理解,并且对需要考虑的有趣变量的构成有一定的洞察力,除了对哪些算法可能会给出更有用的结果有一定的认识,这是有帮助的。
如今,有许多数据科学和机器学习工具可以尝试不同的算法和方法,并在没有太多人工干预的情况下为分析应用程序选择最好的算法和方法。您或多或少地将工具指向数据,指定您感兴趣的变量,然后让它运行。通常描述为自动机器学习平台,这些系统主要销售给业务用户,他们的功能是公民数据科学家,但它们同样受到熟练数据科学家的欢迎,他们用它们来调查比手工做的更多的模型。
即使是最好的模型也可以通过一些变量的调整而得到改进。有时,数据科学家甚至可能想要返回并以略微不同的方式塑造数据——可能会删除在初始数据准备阶段留下的异常值。例如,我看到过许多使用默认值收集原始数据的情况,这些默认值很方便,但却是错误的,可能会引起误解。
4.选择一个模型并运行数据分析
一旦数据科学家找到了针对测试数据集运行的最佳算法,就可以对所有数据运行分析实验了。
有了有趣的假设、良好的数据和精心构建的模型,数据科学家应该能够找到对业务有用的东西。
结果呢?我不能告诉你会是什么。但是,有了有趣的假设,良好的数据和精心构建模型在美国,数据科学家应该能够找到对业务有用的东西。即使在这个阶段,你也会有一个意想不到的发现。大多数情况下,你要么确认要么拒绝你最初的假设——当然,这是你首先要做的事情。
回到我们的销售例子,让我们假设我们决定运行的模式证明,是的,年轻人不太可能购买我们的产品——但有一些重要的曲折,这将引导我们进入下一个步骤。
5.向业务涉众展示并解释结果
请记住,我们实验的全部目的是测试一些想法,然后我们可以把这些想法应用到市场、销售和产品设计中,给他们对我们的客户提供新的见解。
然而,我们所拥有的是来自模型的大量统计数据,业务用户可能无法理解这些数据。或许总体而言,年轻人确实不太可能购买我们的产品——而且,他们的平均购买量也低于那些年纪较大的客户。但一些年轻人买得很多,导致中位销售水平很高。
为了帮助业务涉众理解这种复杂性,数据科学家需要另一种技能——不是额外的技术能力,而是一组技能中的一种他们应该具备的软技能。他们必须能够解释分析工作,讲述数据科学实验及其结果的故事。一些企业甚至有数据解释器或分析翻译他们专门从事这项重要的任务,用业务术语描述分析模型的含义及其发现。他们和数据科学家一样经常使用数据讲故事的技巧澄清分析结果和建议的行动。
6.为生产使用准备和部署模型
现在,我们有了合适的数据,模型可以工作,并且对我们所发现的东西有了很好的业务理解。事实上,业务团队甚至在考虑如何在我们的网站上提供一些优惠,以吸引那些难以捉摸的西方年轻客户。现在我们需要数据科学工作从实验室开始,并在业务运行的过程中,以运营数据的形式投入生产。
最后一步并不总是那么简单。首先,持续使用新数据更新分析模型可能需要采用不同的数据加载方法。我们手工做的实验在实践中可能并不有效。部分出于这个原因,在许多企业中出现了另一个角色:数据工程师,其职责包括与数据科学家密切合作,使模型可以生产。
我们还应该认识到,在我们的例子中,购买习惯会随着时间的推移而改变,或许会随着经济或品味的变化而改变。因此,我们必须保持模型是最新的,也许将来会再次调整它。这也可能是数据工程师的任务不过,如果模型偏离其最初的准确性太多,数据科学家必须对模型进行重新设计。
最后,在实验中效果最好的模型在实践中可能会被证明是昂贵的。随着越来越多的数据分析在云中完成,我们可能会发现一些变化使模型稍微不那么准确,但运行起来更便宜。数据工程师也可以在这方面提供帮助,但准确性和成本之间的权衡可能是一个棘手的选择。
数据科学的商业方面
我已经描述了数据科学过程的基本轮廓。如你所见,有一些元素我们可以称之为工程,甚至是艺术。我们还需要记住,在商业世界中,数据科学是一门生意。也就是说,我们实验的目的和这一过程的成功将始终最有效地集中于直接的商业现实。
因此,数据科学通常比您想象的更具协作性。它不是一门孤立的、技术上晦涩难懂的学科,数据科学家在实验室里独自工作。在最好的情况下,数据科学涉及广泛跨业务和IT领域的协作并为组织工作的许多不同方面增加新的价值。






